I. Introduction
New Positivism, Same as the Old Positivism:
**A Renewed Consideration of The Field through DH and DH through the AI**1
Jonathan E. Abel
(...and Claude Code2)
This article is an updated version of an article I presented twice in 2018 and included as a chapter in in the first draft of the book that later became Studies in Modern Japanese Literature. Since deciding to remove it from that volume to make room for other essays, I have substantially reworked the original piece and am self-publishing here. Here I reexamine of the history of our field through a few of its more recently developed and more avidly critiqued methods, those broadly falling under the label the digital humanities (also known as cultural analytics or computational humanities).
The article examines trends in the field of Japanese Literature over time, in order to examine transformations in our field from a broader vantage than my own individual haphazard readings can afford, doing so through several interlocking datasets. First, I situate Japanese literary studies within the broader landscape of humanistic inquiry by comparing English-language publication trends across six fields of literary study using OpenAlex data, and tracking general cultural interest in Japanese literature against neighboring fields through Google Books Ngram. Second, I examine metadata and statistical occurrence of terms extracted from articles over the last several decades from four of our major journals (Journal of Japanese Studies, Monumenta Nipponica, Harvard Journal of Asiatic Studies, JAS) via publicly available JSTOR data.3 Third, I consider publishing trends in the English language study of Japanese literature against those of dissertations gleaned from data extracted from ProQuest, the Academic Family Tree, and CiNii, forming a little database of nearly eight thousand dissertations spanning 1915 to 2025.4 Fourth, I map the authority structure of the field by layering advisor, book-review, and citation relationships across some three thousand core scholars into a composite network, asking whether the field's training hierarchy and its intellectual hierarchy produce the same rankings. Fifth, I examine conference presentation data from five venues — the Association for Japanese Literary Studies, the Association for Asian Studies, the Modern Language Association, the American Comparative Literature Association, and the Society for Cinema and Media Studies — totaling over twelve thousand presentations from 1992 to 2026.5 Sixth, I look at historical changes in job offerings via data from MLA, H-Japan, and ATJ job advertisements and positions in the field, now covering the full period from 1966 to the present.6 Lastly, I look at the changing relationship between translation and scholarship in Japanese literary study by examining the correlations between translations and scholarly publications.7 Ultimately, the article remains my attempt to assess whether such a data-driven approach will lead us to any conclusions besides what we could have garnered through intuition, personal impression, experiences of working in the field, and, of course, close reading.
This methodological examination itself will give some insight into how the field might be changed by such recent methods, the state of digitization (and, even more recently, AI infestation (about which more later)), and the ways in which the field may continue to remain unchanged despite such changes. Before beginning a dive into the research, it may be necessary to acknowledge that one of the differences of this kind of research is that it is necessarily or more obviously collaborative than most literary critical work. Like traditional or analog humanities research, the following research relies on the work of institutional information curators; if not librarians, at least the data managers of the resources I use are both worth mentioning and praising here for their archival and preservationist efforts as well as worth remaining critical towards because skepticism about what is selected for preservation, deemed worthy of counting, and actually possible for inclusion remain as decisive problems for digital archives as they are for analog ones. Just as no paper archive is complete, every digital collection of data is rife with human error and problematic data entry and gathering processes;8 in short no archive is an objective material infrastructure but one prone to similar subjective issues as a poem. However, as with poetry, the unevenness in archives has never been a reason to abandon that which they contain, but rather cause to remain cautious and vigilant in considering that which they hold; source criticism is the first lesson for any humanist.
So a project is only as objective as its data which is to say not objective. We tacitly collaborate with those who collected or provided the data every time we use it. And further, perhaps more than traditional humanist source collection, digital humanities work seems to requiressa more openly collaborative method. My research assistant Kendra McDuffie helped digitize data on MLA job searches dating back to the 1960s; my son Ben helped collect job advertisements from the web from the early 2000s; Mark Ravina helped with parsing and writing R code to analyze trends in JSTOR data; and Claude, an AI developed by Anthropic, assisted in data pipeline construction, visualization development, and the drafting of portions of this new 2026 version of the essay — a collaboration whose implications I will return to in the conclusion. So already this study has worked with a Japanese literature scholar, a lay person, a scholar in the wider arena of Japanese Studies, and an artificial intelligence that has zero experience of the world, let alone Japan, Japanese literature, or its field. Of course, this collaborative aspect of DH is part of all research, but (for better or worse) it tends to be sidelined and forgotten.
I think the nature of the scale digital humanities questions and solutions requires us to make it part of the spoken (and written) practice. And the addition of AI collaboration only sharpens this point: as the solitary approach is sacrificed for a perceived broader view of a larger scale, the fact that DH so blatantly draws on the work of so many different institutions, people, and now machines means that in the process it has already dealt a blow to the myth of individual control over critique. In short, the thinking about methods which is so big a part of the work of the social sciences and all too often ignored in literary criticism comes back with a vengeance in digital humanities to expose the contingency of traditional literary critique from the beginning. More data does not resolve this contingency. As positivism shows again and again, such studies are always incomplete; what changes is the precision with which we can narrow in on what we do not yet know.
II. General Interest
Let me begin with some general visualizations about English language world interest in Japanese culture. Based on my readings of other states of the field essays over the past few decades or so,9 my own experiences, and those of my randomly queried friends in the field, my hunch is that when people say the field is over, or peaked long ago, or lament what has become of the field (I'm talking not just about the most prominent versions of this (Karatani Kōjin's post-millenial laments or John Treat's more recent book10) but a general sentiment one that extends beyond Japanese Studies to all of the Humanities in North American context), they are talking about a specific modes of inquiry, typically the ones they themselves found compelling, and spent time developing. Such remarks tend to be either a nostalgia for an ideal time that may or may not have existed in the past or a gross misreading of the situation today—such as, the day when the only thing that passed as literary was the canon, the day when the canon was high culture, the day when language mattered, and the day when students did the reading. Much of my interest in a data driven approach here is to get beyond personal feelings about the field and try to see it for what it was, may still be, and what it is becoming. But as I've been getting more into it, I realize how subjective even this data driven approach really is. And I'll come back to this at the end of this article.
We can start with a deceptively basic and simple issue: is the field growing or shrinking in comparison to neighboring fields? Answering it precisely turns out to be harder than it looks, because "the field" exists on several registers simultaneously: for example, it can be measured in general English-language cultural discourse, within academic publications, and as institutional infrastructure. These are not the same thing and do not move together. What follows is an attempt to glean a sense of each.
Since I began studying Japanese literature in the North American context in the 1990s, I'd been told that the conventional wisdom was that in language learning over the course of the postwar (say, from 1945 to 1990) when Chinese language learning was up, Japanese language learning took a hit at North American Universities. In more recent years, I've heard colleagues express surprise at times that Japanese language learning enrollments were holding in comparison to Chinese at some universities (particularly before the 2008-2010 economic downturn). But I've also heard that this has less been the case since the downturn. That enrollments across the board are down. But this is anecdotal and about language. What about the relative rise and fall of Japanese Literature?
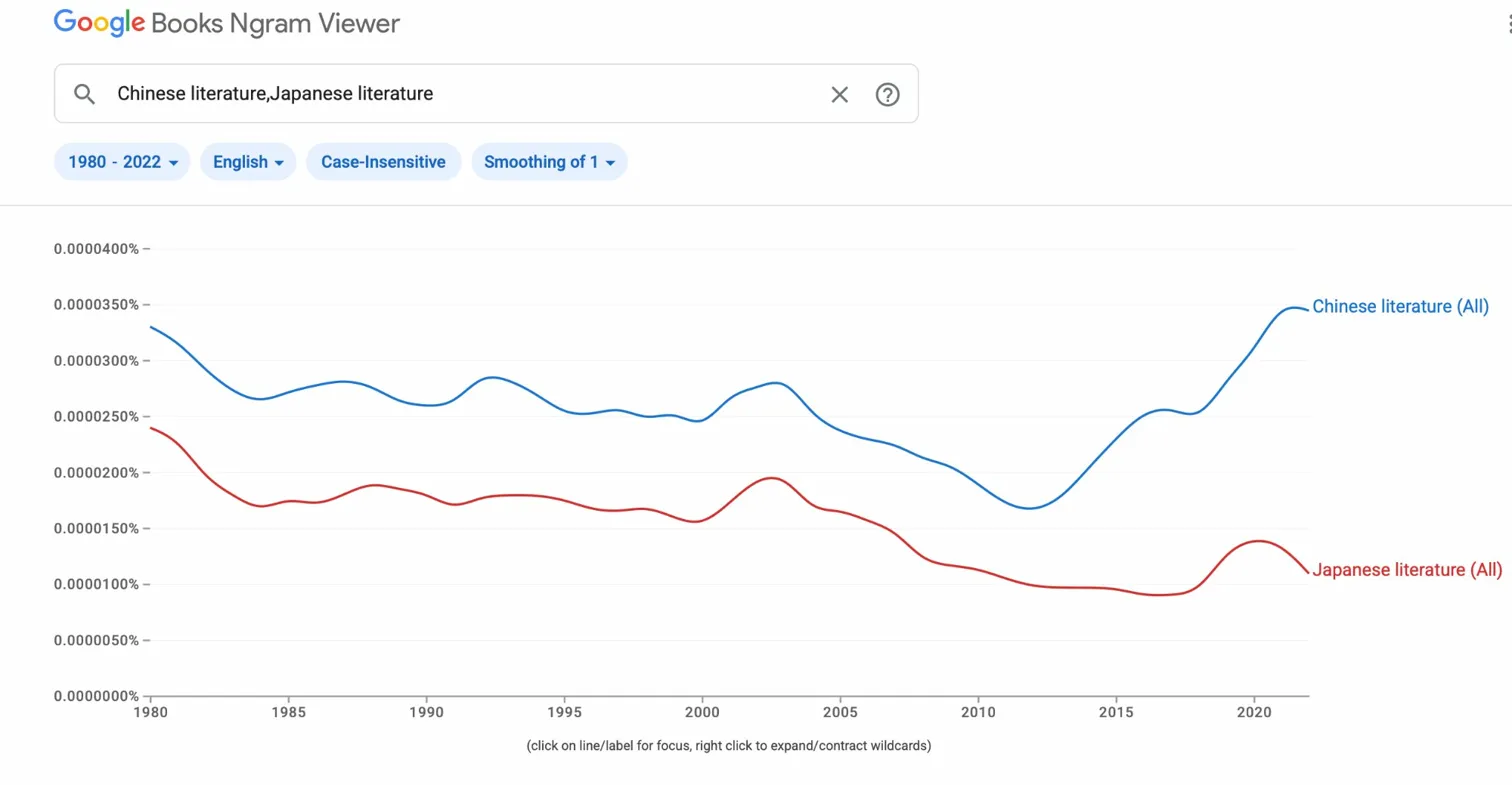
Google Books Ngram measures bookish conversation — how often terms appear in the corpus of digitized books published in English. It is a rough instrument, but it measures something real: the degree to which a subject has penetrated mainstream written culture. The chart for "Japanese Literature" vs. "Chinese Literature" from 1980 through 2022 tells a clear story with one major revision from what appeared in my earlier study. There is a visible"Japanese Literature" peak around 1996 — interpretable as the tail of the Japan bubble cultural moment, the Murakami boom, and the last decade of print-dominated literary culture before internet fragmentation. What the extended timeline (beyond my first glimpse in 2018 with data that extended only to 2014) now shows is that "Chinese Literature" and "Japanese Literature" track together through the 1990s and 2000s, moving in rough parallel rather than in opposition. The conventional wisdom that Chinese cultural interest comes at the expense of Japanese is not supported by this data. What the 2010s show is simply a dramatic rise in Chinese — not a displacement of Japanese, but an expansion of the entire space. East Asian literatures as a discussion in English books are not playing within a zero-sum attention span for East Asian literatures. The floor for "Japanese Literature" after 2000 is flat rather than collapsing; the ceiling for "Chinese Literature" has simply lifted dramatically.
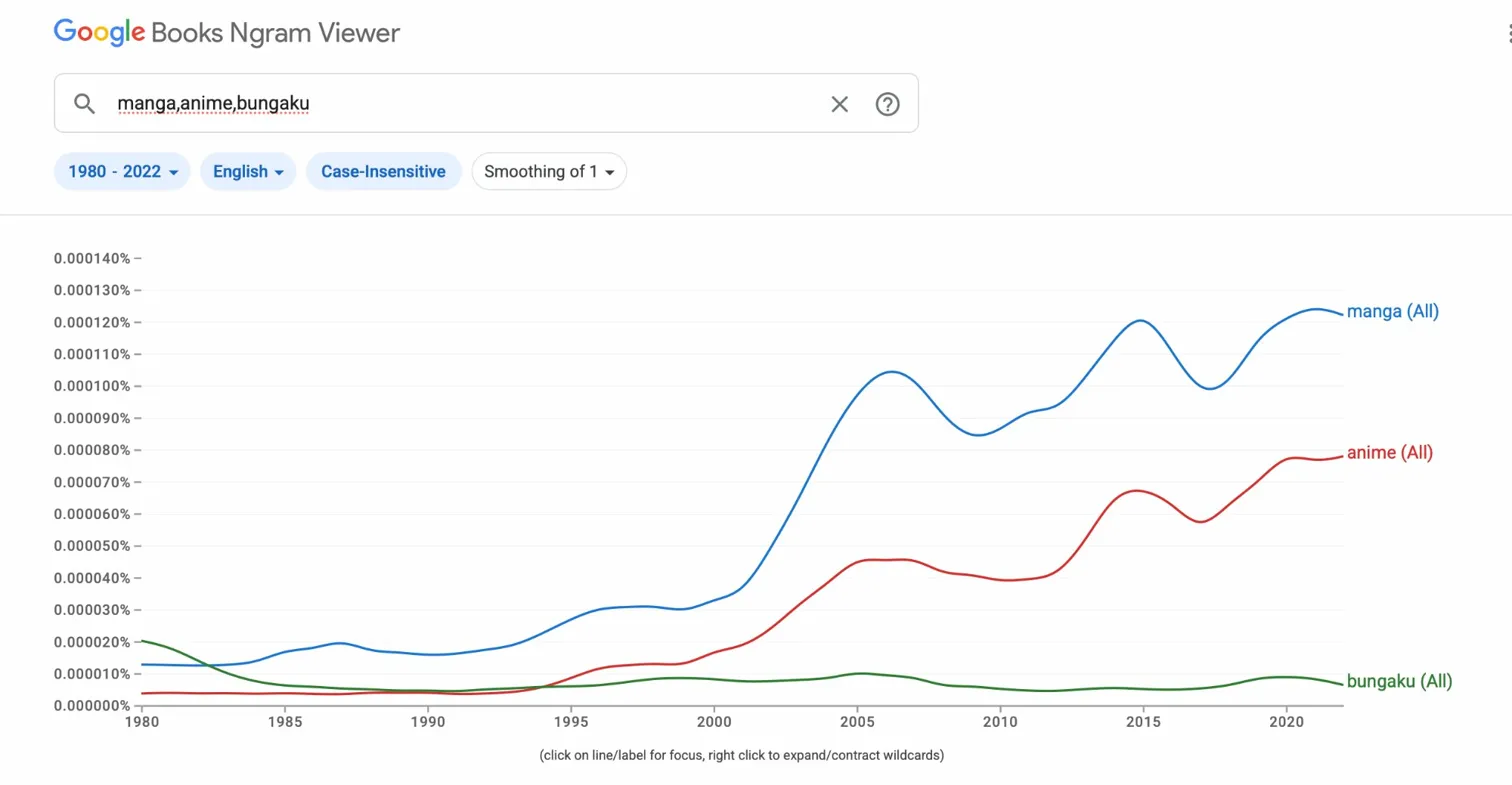
The second set of Ngram charts — tracking manga, anime, and bungaku and manga, monogatari, and shōsetsu as loan-word proxies for Japanese popular vs. literary cultural penetration in English — remains essentially unchanged from earlier analysis. Manga and anime surpass the literary terms by the late 1990s and continue to dominate through 2022. This is not news, but it is important context: the general English-language cultural interest in things Japanese has long been more popular than it is literary, and the gap has only widened in recent years. The bookish conversation about Japanese literature that such Ngrams capture is a small fraction of the broader conversation about Japanese culture. Unlike in language circles where it is argued to have helped maintain numbers in the classroom, there has also been some discussion today how the study of pop culture killed Japanese literary study. This next graph seems to show that while English language use of the Romanized Japanese "bungaku" seems to have had a bit of a bubble from 1992 to 2005, general interest gauged in bookish mention of manga and anime had far surpassed their more high brow older cousin around the millenium. Similar trend lines show this to be the case for both monogatari and shōsetsu vs. manga.
English-Language Literary Scholarship by Field, 1945–2024
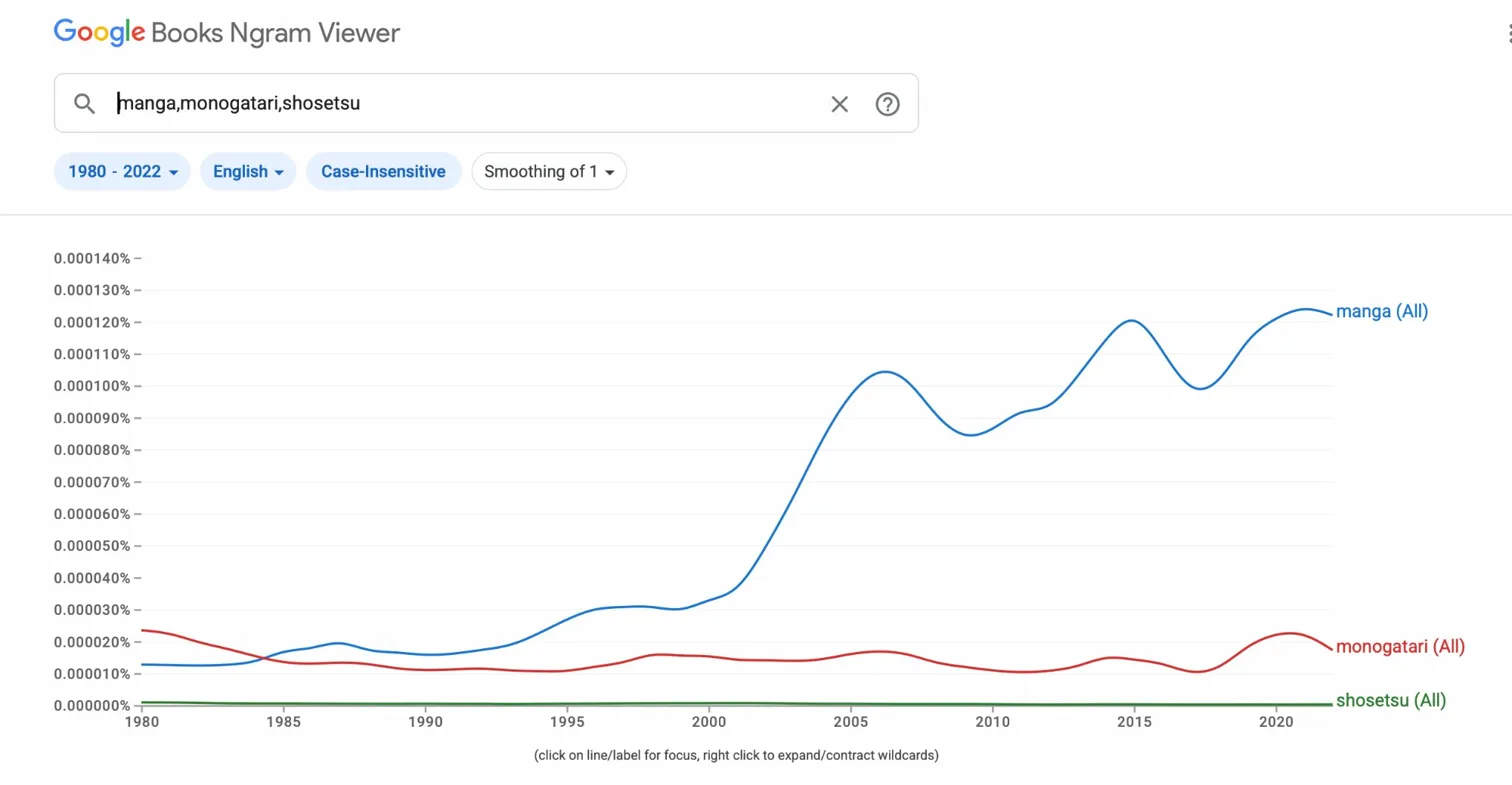
Notable here is the fact that shōsetsu the modern narrative is a consistent looser to monogatari. One piece of data that counters the general sense that modern Japanese literature is of greater popularity than premodern (though it likely has more to do with the general place of the Tales of Genji in world literature and discomfort for translating monogatari as novel verses the perhaps higher level of comfort in translating shōsetsu as novel, than it does with a pervasive lust for premodern studies).
All of this gives a sense of the mainstream English language awareness of Japanese literature. But what specifically of scholarly work? Well, google has an app for that too ....or sort of. To get a sense of the general predominance of different fields of literary study, we can query OpenAlex, a fully open bibliographic database covering 200+ million academic works, queried for English-language articles in each of six fields: Japanese, Chinese, French, German, American, and Comparative literature. The results are snapshots rather than complete censuses — OpenAlex coverage varies by journal and field, and there are known indexing asymmetries, particularly for specialist Japanese-field journals before 2000 — but the post-2000 data is substantially more reliable and the directional findings are clear enough to use.
The headline comparison for 2000–2024: Japanese literature runs at roughly 60% of French and German, well behind American literature (which dominates absolutely), and has been surpassed dramatically by Chinese literature, which now stands at 3.7 times Japanese literature in the same period. My 2018 claim that Japanese literature scholarship in English was "roughly on par with French" by the 2000s overstated the case; the more accurate description is that it runs meaningfully below French and German, though the gap is partly a coverage artifact — the flagship journals of French literary studies have far denser OpenAlex indexing than their Japanese counterparts.
What cannot be explained away as a coverage artifact is the robustness of the gap across multiple independent query strategies. Tested against a baseline search, an expanded search using 48 literary-theory vocabulary terms derived from corpus linguistics research, and a filtered search requiring the vocabulary of literary hermeneutics (narrative, poetics, rhetoric, hermeneutic, intertextuality, and their kin) while excluding STEM terminology — the French/Japanese ratio across 2000–2024 holds at approximately 1.65 in every formulation, meaning that for roughly every two articles on Japanese literature, there are three on French.¹ This consistency across four independent measurement strategies is the strongest evidence that the gap is real rather than methodological.11
The same analysis yields a secondary finding that turns out to matter for how we understand the field: retention rates — the fraction of each field's baseline count that survives the literary-theory vocabulary filter — are nearly identical across fields, with Japanese retaining 51% and French 54%. Japanese literary scholarship in English is essentially as theory-inflected as French literary scholarship; it uses the same critical vocabulary of narrative, poetics, and interpretation at virtually the same rate. The volume gap is not a gap in intellectual character. Japanese literary studies in English is a smaller field than French, but it is not a less theoretically engaged one. In other words, Japanese literary studies in English tend to speak in the same critical lingua franca as other critical traditions.
III. Journals
To glean a sense of the discourse within academia, I have chosen to draw on JSTOR Data for Research. In 2018, this meant doing word frequency counts from journal articles in five periodicals that constitute a core of English-language Japanese literary studies: the *Journal of Asian Studies (JAS), the Harvard Journal of Asiatic Studies* (HJAS), Monumenta Nipponica (MN), the Journal of Japanese Studies (JJS), and Positions: East Asia Cultures Critique. The present analysis draws on a refreshed JSTOR export covering 29,311 articles from 1936 through 2020, ingested into the project database with term frequency counts computed for 94 tracked terms. The findings both confirm and extend what the 2018 analysis found.
The broadest finding is that the theory turn in Japanese literary studies was not a moment but a decades-long ratchet, and it has not reversed. The terms with the largest proportional increase from the 1990s to the 2010s are: narrative (+0.223), modern (+0.185), discourse (+0.180), modernity (+0.170), gender (+0.149), media (+0.145), and body (+0.107). Postcolonial, nationalism, and subjectivity also rise. The presence of modernity as the fourth-largest riser — distinct from modern and ranking above both gender and discourse — reflects a substantive shift in how the field frames its historical questions: less the periodization of "the modern" as a chronological marker, more the conceptual apparatus of modernity as a condition to be theorized. Body ranking ninth reflects the corporeal and affect turns that reshaped literary studies broadly in the 2000s and 2010s and moved through Japanese literary studies with perhaps a decade's lag. None of the eight terms shows any decline from the 1990s to the 2010s — including colonialism, nationalism, and race, whose rises are more modest but consistent.
The falling terms are equally telling. Modest but consistent declines appear for postmodern (−0.014), eiga (−0.014), Kamakura (−0.014), Sōseki (−0.012), and Shōwa (−0.012). The pattern here is field broadening rather than field decline: canonical author names recede as a proportion of all articles because more articles are now about less-canonical figures; period names recede because scholarship has become less tethered to the standard periodization framework. The field is not abandoning its subjects — it is adding new ones faster than it revisits old ones.
The journal-by-journal character is now quantifiable rather than merely impressionistic. Theory density — the share of articles containing at least one of ten core theoretical terms (theory, critical, discourse, ideology, representation, deconstruction, postcolonial, feminist, queer, subjectivity) — ranks the journals as follows: Positions (0.329) \> HJAS (0.234) \> JJS (0.204) \> MN (0.150) \> JAS (0.122). Positions at the top is unsurprising given its explicit theoretical-critical mandate. HJAS ranking second is less obvious and deserves a note: its relatively small article corpus means that individual theory-intensive special issues or runs of articles carry disproportionate weight. The ordering of JJS above MN confirms the 2018 impression that JJS tracks the theoretical mainstream of literary studies more closely than MN, which retains a stronger philological and textual character.
The orientalism anomaly first noted in the 2018 analysis survives the refreshed data and deepens slightly. HJAS shows appearances of orientalism in articles from 1936, 1938, and 1951 — well before Edward Said's Orientalism (1978) made the term a critical concept rather than a descriptive category. This is not a data error: these are cases of the term used self-descriptively, as scholars in those decades described their own enterprise as the study of the Orient. The genuinely interesting finding is that JAS shows a sharp spike in orientalism usage in 1980 — almost certainly a cluster of response articles to Said published in the immediate aftermath of the book — and then sustained elevated use through the 1990s that only begins to taper in the 2000s. The data cannot tell us whether those 1980 JAS articles were embracing or contesting Said, only that they were invoking him. That question, like most interesting questions, requires reading.
The manga trajectory in this data is flatter than intuition would suggest. The term rises in the 2000s but never achieves the dominance in these journals that the Google Books Ngram analysis shows in general English-language discourse. This is consistent with the hypothesis that manga scholarship in English has largely developed outside the core journals — in film and media studies venues, in comparative literature, in the SCMS and ACLA conference circuits — rather than transforming the journals that were there first. Conference data confirms this: manga and anime topics appear more heavily in SCMS and AAS than in AJLS, the dedicated Japanese literary studies venue.
This last observation points toward a limitation of journal-based frequency analysis that the 2018 paper could identify but not remedy: journals are lagging indicators. The time from research to publication in peer-reviewed journals runs four to seven years on average; the time from conference presentation to journal article adds another layer. The term trends in these five journals describe what Japanese literary studies was doing in the past, not what it is doing now. The conference presentation data developed for this project — 12,200+ presentations across five venues from 1992 to 2025 — functions as a leading indicator for the same processes. Where journal data shows gender rising through the 2010s, conference data shows what has been building in the 2020s: ecological approaches, infrastructure studies, the renewed interest in translation as a scholarly problem rather than merely a practical one. The two sources are complementary rather than redundant. The journals tell us where the field has been; the conferences tell us where it is going.
V. Dissertations
I've also been examining dissertation data — titles, abstracts, dates, institutions, advisors, writers — from a variety of sources. Such data can allow us to find out which institutions produced the most PhDs and which scholars advised the most people in the field, though as with the other datasets examined here, what it can tell us is always a function of what it was designed to capture and what got left out.
The dissertation database I've created has grown from 1,545 records in 2018 to 7,922 today — but that number requires an immediate methodological caveat the 2018 version didn't need to make. The original dataset was drawn entirely from ProQuest Dissertations & Theses, which indexes North American doctoral programs almost exclusively. The 2025 database integrates three sources: ProQuest (2,541 records, 32%), a 2025 RIS batch update from that resource (513 records, 6.5%), and CiNii — the Japanese National Institute of Informatics dissertation index (4,376 records, 55%). The result is a genuinely binational dataset covering both Japanese and North American doctoral production in Japanese literary studies from 1915 through 2024. Where the 2018 analysis described the North American field, the 2025 version describes something closer to the full scholarly field — and the two are not identical. Japanese doctoral programs produce differently shaped dissertations, supervised by differently positioned scholars, on topics that do not always map onto the periodization and theoretical preoccupations that dominate North American graduate training. And in general the Japanese data lacks advisor names and abstracts. That difference is a finding in itself, though one that would require its own analysis to develop fully.
With that caveat registered: in aggregate the expanded dataset seems rather robust. A graph of dissertations by year comports with the general sense that the 2000s were the true high-water period for the field, with production peaking in 2009 at 313 dissertations and the five highest-production years clustered between 2006 and 2012. The 1990s produced 1,173 dissertations across the decade; the 2000s nearly doubled that at 2,571; the 2010s pulled back slightly to 2,307. The 2020s show 786 across six years, with 2023–24 figures still accumulating in the indexes. The COVID-era dip is visible but not as catastrophic as the job market data suggests: 140 dissertations in 2020, 159 in 2021, 141 in 2022. PhD programs continued producing graduates even as the job market for those graduates briefly collapsed to a 138:1 supply/demand ratio — which is perhaps its own comment on the inertia of the training pipeline.
We might all have some predictions about how the advisor data would go: Keene, McClellan, McCullough, Miner, maybe followed by Miyoshi and Sakai, then Rubin, Tansman, Treat, Bourdaghs, and Shirane. Such hunches are to some extent borne out — the names are right, even if the order surprises.
Shirane Haruo (Columbia) leads at 43 advisees across 1997–2023, up from 28 in the 2018 count. Edwin McClellan (Yale, then Chicago) and Alan Tansman (Berkeley) are tied at 31, with McClellan's count nearly doubling from the 15 reported in 2018 — a correction attributable to better source coverage rather than posthumous advising. John Whittier Treat (Washington) follows at 28. And Norma Field (Chicago) at 26 stands out as among the most consequential advisors in the field, a fact that perhaps deserved more attention in the 2018 version than it received. The deeper interest, though, is less in the rankings than in the realization that the advisees and advisees-of-advisees sprouting from Edwin McClellan comprise something like the trunk of the intellectual family tree of North American Japanese literary studies.
As for Donald Keene: only four advised dissertations turned up in the 2018 set and seven in the expanded corpus — which is either a remarkable dereliction of duty by the king of English language study of Japanese literature or by the institution that archived the dissertations. A scholar of his stature and longevity should have more than Zolbrod, Ruch, Rimer, Matisoff, Bernardi, Qiu, and Cipris to show for decades at Columbia. Columbia's ProQuest indexing gaps for early decades are well-documented, and the seven likely represents a floor rather than a count — but the 2018 essay raised a data question that the 2025 version can only partially answer.
The more significant upgrade from 2018 is not the counts but what we can now do with them. The original analysis showed a flat bar chart of advisee totals. The 2025 version has full multi-generational genealogy chains derived from Academic Family Tree integration: Keene advises Rimer who advises X; Shirane advises Y who advises Z. The average advisor-advisee topical overlap score is 0.841 — high, suggesting that students largely work within their advisors' intellectual territory rather than departing from it. The field reproduces itself with considerable fidelity across generations, which is either a sign of intellectual coherence or of a training pipeline that narrows what counts as Japanese literary studies. The data cannot adjudicate between those interpretations; it can only make the pattern visible.
If we turn to the content of the dissertations themselves, the 2018 analysis tracked topics through title keyword frequency and abstract term counts — a methodology honest enough about its own limits. As I noted then, all of this frequency representation is more about mention than it is about substance or meaning; disclaimers in the abstract that announce "this dissertation will not focus on poetry" count as "poetry" to the same degree as statements of scope like "this dissertation will deal exclusively with poetry." The 2025 version uses NLP semantic classification across 20 topic clusters, achieving 88.9% coverage of the 7,922 records — up from the 34.3% coverage the keyword method managed. The difference is not merely quantitative. Semantic classification catches the dissertation about Bashō that never uses the word "poetry," and distinguishes the one about Meiji-era political novels from the one that happens to mention Meiji in passing.
The findings both confirm and complicate 2018's intuitions. Meiji-period scholarship remains by far the dominant cluster. The "women" finding — that dissertations with women as subjects appeared at a surprisingly high rate in title data — is confirmed and clarified: gender and sexuality constitute a distinct topic cluster with a clear trajectory, rising through the 1990s and plateauing in the 2000s rather than continuing to climb indefinitely. My supposition would have been that poetry would not really compare with prose literature or fiction in terms of frequency of study — and while the data does show a clear predominance of prose, poetry dissertations show an increase in recent cohorts rather than the decline that intuition and the relative prestige of fiction in the anglophone academy would suggest. Premodern forms — waka, haiku, renga — are holding their share of doctoral production even as the broader field's journal vocabulary tilts toward modernity and theory. What to make of this is not obvious; the data raises the question more confidently than it answers it.
What still stands out, as it did in 2018, is that "monogatari" appears more frequently than "shōsetsu" across nearly the entire forty-year period — a counter to the armchair supposition that modernity dominates. Whether this reflects genuine scholarly interest in premodern narrative forms or simply modernists' greater comfort translating shōsetsu as "novel" and leaving it untranslated, the pattern persists in the larger dataset and remains worth investigating.
VI. Job Market
MLA gives out data for free, back to 2000. Working with my research assistant and son to digitize job advertisement data back to 1967 — the earliest extant job lists from the MLA — and then to correlate advertisements with hires and publication data, we have since extended that collection with data from H-Japan, AATJ, and university websites, ultimately arriving at 2,371 confirmed job listings spanning 1966 to 2025. What was preliminary in the 2018 version of this essay is now, if not complete, at least comprehensive enough to test the hypotheses that earlier version could only propose.
The graph above gives us a relative sense of how jobs in Japanese literature have fared in comparison to the aggregate number of jobs listed by MLA. As noted in 2018, there was an absolute downturn in the number of Japanese literature positions after 2008; as a relative portion of the major downturn of jobs in the MLA writ large, Japanese studies fared relatively well, increasing its portion of the MLA pie. I suspected at the time, given the low absolute numbers of jobs in the period studied, that this was simply a random anomaly having to do with local replacement issues and hiring practices of a handful of institutions over a matter of years. The longer view suggests this was roughly correct — the relative stability was real but not structural — but the longer view also reveals something I did not anticipate.
Job calls represent the institutional desires written often by people outside of the field for what the field should or might become. To that extent they are future-oriented but not particularly perceptive. But they are in a sense the culmination of perceptions as to where a field currently is, and therefore presentist or even nostalgic in their desire to sustain something of the past. In other words, like all genres, job ads are both descriptive and prescriptive.
We can also look at the substance within the text of the advertisements. In the long 1970s (1967–1980), there were only 196 postings mentioning Japan, with 15 mentioning "Japanese literature." The following decade had 748 mentions of Japan, with 79 mentioning "Japanese literature." What seemed most substantial in the 2018 analysis was the higher frequency of the phrase "tenure track" in the 1980s, suggesting growth and investment in the field. The keyword evolution from the 1990s through the 2010s confirms earlier intuitions: the distinction between modern and premodern arose in the 1980s and was solidified in the 1990s; the 2000s saw expanded cultural studies framings alongside a fading of premodern specialization in job ads; and film and media positions appeared earlier than my original hunch suggested, beginning in the late 1990s rather than the 2000s.
The headline finding of the expanded analysis was not visible in 2018, because it had not yet happened. In 2018 I wrote that Japanese literary studies appeared to be "dying at about the same rate as the rest of the field as measured in jobs posted." The 2024–25 data requires me to revise this sentence substantially. What the supply/demand analysis reveals is a field that collapsed almost entirely during the COVID years — 2 jobs in 2020, 2 in 2021, 1 in 2022, producing a ratio of 138 PhDs per available position in 2022, the worst oversupply on record — and then recovered with a speed that surprised everyone, including presumably the institutions doing the hiring. In 2023 the ratio was essentially balanced at 1.02:1. In 2024 and 2025 it inverted: 0.92 and 0.75 respectively, meaning more jobs than PhDs in each of the past two years. The last time this happened was 1988, at the peak of the Japan bubble economy.
The overall historical ratio since 1966 is 2.90 PhDs per available position — chronic oversupply is the baseline condition of the field, not an aberration. Against that baseline, 2024–25 represents a structural anomaly. Whether it is temporary or the beginning of a new condition depends on factors the data can identify but not resolve: the retirement wave of the 1970s cohort of Japanologists now reaching their seventies, the three frozen years of COVID searches now releasing simultaneously, new Asian studies institutional initiatives in the post-pandemic period, and a PhD pipeline that contracted sharply during the pandemic and has not fully recovered. Any of these would be sufficient cause individually; together they have produced the first sustained undersupply in 37 years.
My original hypothesis was that dissertations are about five to ten years behind the job market — that people see a cluster of positions, encourage their current students to pursue this course, and those students finish their dissertations long after the hiring trend has passed. The data is now sufficient to test this conjecture directly. Initial analysis suggests the lag is real but unevenly distributed: the signal is clearest at the peak of the production curve (2006–2012) and weakest in the COVID-era collapse, where the drop in positions was so sudden and so total that no ordinary lag process could have prepared the pipeline. The detailed analysis remains ongoing, but the directional confirmation holds: the training pipeline does follow hiring rather than lead it, and by the time the field responds to a market signal, the signal has usually moved on. The current moment — with more jobs than available PhDs for two consecutive years — is precisely the condition that should, on the lag hypothesis, trigger a surge in graduate enrollment. Whether it will remains to be seen.
The supply/demand numbers describe the field's aggregate metabolism. A different question is where the field's graduates actually go — and whether the training institutions that produce the most PhDs are also the institutions that absorb them. The career trajectory data, drawn from 1,571 scholars with both a recorded PhD institution and a current or recent institutional affiliation, produces a placement matrix that rewards inspection. The expected pattern holds in outline: Columbia, Chicago, Harvard, and Michigan place widely and well. What the matrix makes visible that intuition does not is the degree of self-placement — the proportion of an institution's graduates who end up at comparable or peer institutions versus the proportion who circulate broadly — and the difference between programs that train for the R1 market and those that train for the teaching-focused market. A chord diagram of PhD→employment flows for the top twenty institutions shows the major pipelines; a swim-lane career timeline for 349 scholars with documented career moves shows the lateral movement that aggregate placement data erases. The finding that will not surprise anyone who has served on hiring committees, but that is clarifying to see quantified, is how few institutions account for the majority of R1 Japanese literature hires.
What about the lag of ideas more generally? When and where are the most innovative moments of a career or of the field? Is it the dissertation? Articles? Books? Reviews? Is there a time lag from when discourse about a topic in dissertations makes it into journals? Or is it the other way around that dissertations follow what is in journals? How would we trace such cycles in academic discourse? Chicken or egg? Is there a correlation with job ads? In other words, does an article in JJS lead to a transformation in how people think about the field and define jobs? Or does a job position that, when filled, promote a new kind of scholar/ship? When do trendy terms from PMLA find their way into conservative area studies journals? Is there ever a reverse flow? What leads and what follows? Where is the most experimental work of the field? In dissertations where young scholars are being disciplined to norms and standards? In work of tenured scholars where scholars might feel safer to pursue cutting edge work that pushes the norms and standards? Which advisors are the most effective at mentoring junior scholars? Is this institutionally or personality bound, or some combination of the two? We could measure this in a number of ways but looking at longevity in the field, publication data, and job data could be relevant here. This is just about numbers, but we can also use this to mark whose students get published the most, whose get hired, whose publish more books etc. In other words, data could potentially tell us quite a lot about our field.
But there are also things that we certainly cannot do with such data: the cannot tell us if the most effective advisor, for instance, was the also most neglectful advisor—forcing their students to struggle in the field, or the most hands on advisor coaching about every aspect of academic and scholarly life. The data cannot tell me why I didn't get a job in 2004, 2005, or 2006; data cannot show me why a certain article got rejected. In addition, it cannot tell what a successful play through of the game of academia looks like; who is to say whether success can or should be defined by a dissertation converted to a book and reviewed in a major publication; who is to say whether a tenure track position at a research institution (certainly not someone like me who is in such a position) with major research? This is not a question of whether it is a book or five articles (as is oftent he case with major teaching positions) but rather whether data analytics can suffice to account for the entirety of the work being done and contributing to our academic community. To be sure the financial and status glories do seem to be defined along such rigid neoliberal economic lines of measurability, but that does not mean we as a community need to adhere to them. What data can do is this: it can tell us how common or uncommon such playthroughs are; it can give us the state of the field but not the explanation of the field for that we still need interpretation and critique; it can make us rethink our assumptions about particular aspects of the field, but it will not dictate where that rethinking will lead.
What the data can tell us is this: it can give us the state of the field but not the explanation of the field; for that we still need interpretation and critique. The 2024–25 reversal tells us something happened. It does not tell us whether Japanese literary studies is experiencing a genuine institutional recommitment, a one-time demographic correction, or a market spike that will reverse by the time anyone reads this sentence. Those questions require the kind of leaps from the data that the data itself cannot authorize.
VII. Conferences
The 2018 version of this essay used MLA data for one purpose: counting job listings. It did not occur to me at the time — or rather, it occurred to me but seemed impossibly labor-intensive — to treat conference programs as a data source in their own right. Conference programs are poorly preserved, inconsistently formatted, spread across a dozen different platforms and two decades of changing web infrastructure, and not indexed by any single resource. They are, in other words, exactly the kind of source that rewards the kind of obsessive, semi-automated, occasionally maddening data collection that digital humanities work tends to generate.
The 2025 version has data from five venues: the Association for Japanese Literary Studies (AJLS, 26 conferences, 1,153 presentations, 1999–2025), the Association for Asian Studies (AAS, roughly 2,900 Japan-relevant presentations after filtering from a raw harvest of 7,228, 1995–2025), the Modern Language Association (MLA, 2,502 presentations, 2004–2026), the American Comparative Literature Association (ACLA, 861 presentations, 1992–2026), and the Society for Cinema and Media Studies (SCMS, 2,803 presentations, 2008–2026). In aggregate: over 12,200 presentations spanning 34 years. This is a different kind of evidence than journals or dissertations. Journals are the field's formal record; dissertations are its training record; conference presentations are something closer to its social record — who shows up, who panels with whom, which institutions are represented, which topics get airtime before they reach print.
Some caveats on the data before proceeding. Conference programs present different methodological challenges than ProQuest or JSTOR. The AAS harvest required three separate scrapers — a Confex API for recent years, a PDF parser for 2013–2019, and a Wayback Machine crawler for the 1995–2012 legacy HTML programs — and after applying a Japan-relevance filter, 40.1% of the raw harvest survived. SCMS was more extreme: only 24.3% of its 2,803 presentations turned out to involve scholars with any connection to Japanese literary or media studies, which is itself an interesting number — it means SCMS reaches the field but the field is a minority presence in SCMS. AJLS requires no filtering at all, being entirely dedicated to the field, which makes it the cleanest dataset and, in some respects, the most analytically useful.
The match rate gradient across venues tells a story worth pausing on. AJLS presenters match the dissertation and career database at 76.7% — nearly all of the field's specialist conference is the same population as the field's doctoral program network. AAS runs at 66%, reflecting a broad Japan studies overlap. ACLA drops to 36.8%, and SCMS to 21.3%. This gradient is a quantification of disciplinary distance: the further from the Japan-specific conference circuit, the smaller the proportion of presenters who are part of the core scholarly network. It sounds obvious when stated that way, but it was not previously measurable.
The institutional question — I'm still lookin' at you, Columbia — turns out to have a more complicated answer than I would have guessed. By multi-venue presence (the number of different conferences at which an institution appears), Princeton leads with 91 presentations across 5 venues, followed by Tokyo (41, 5 venues), Stanford (39, 5 venues), Chicago (66, 4 venues), and Yale (48, 4 venues). Columbia appears in these counts too, but not at the top. What the multi-venue data suggests is that the field's social center of gravity and its dissertation-production center of gravity are not the same place — which may mean something about how the field reproduces itself intellectually versus how it circulates.
The finding I did not anticipate concerns the MLA specifically. In 2018 I used MLA data only for job listings and treated the convention itself as background noise. The conference presentation data tells a different story. When I searched MLA programs not just for Japan-themed sessions but for presentations by scholars in the dissertation and career database — that is, looked for where Japanese literature scholars actually show up in MLA programs regardless of session title — I found 913 additional presentations that keyword search had missed entirely. These scholars are presenting on theory, translation studies, comparative method, and disciplinary questions in panels that are not labeled Japanese anything. The cross-disciplinary engagement rate turns out to be 41.7% of total MLA presentations by field members: nearly half of what Japanese literature scholars do at MLA has nothing to do with Japan as a session category.
This is perhaps unsurprising to anyone who has attended MLA and knows that the interesting panels tend not to be the national literature subdivisions. But it was surprising to me as a data finding, because it means that the 2018 essay's implicit model — Japanese literary studies as a self-contained zone within larger disciplinary structures — is not borne out by what scholars actually do at conferences. The field is more integrated into the broader conversations of literary studies, comparative literature, and theory than a keyword-based accounting would suggest. The SCMS data points in a similar direction: 24.3% retention means a meaningful minority of Japanese studies scholars are presenting regularly in a venue dedicated to cinema and media, often on panels with no Japanese content in the title. These are populations — one might call them the comparatists and the media scholars — with career trajectories and publication records that look different from those of the area studies core.
The AJLS data, precisely because it is the cleanest, also illuminates something the broader conference data cannot. Twenty-six conferences over 26 years, 729 distinct scholars, 289 panels, 559 institutions. The geographic diversity trend is visible in the data even without statistical testing: Japan-based institutional representation at AJLS grows from a small fraction of early conferences to a consistent presence in recent years. The field has become more transpacific in its actual conference attendance, not just in its stated intellectual commitments. Whether this represents a genuine internationalizing of the North American field or simply the increasing ability of Japanese scholars to attend North American conferences is a question the attendance data alone cannot answer. But it is no longer just a hunch.
All of which is to say that the conference data, taken alone, describes a field with permeable boundaries and an increasingly cross-disciplinary center of gravity. But the conference data is not alone. The field connections map assembles the full relational infrastructure of the dataset: 1,229 nodes and nearly 5,000 edges combining advisor relationships, conference co-appearances, book reviews, citations, and career connections across all five venues. It is the visualization I find most honest about what this project is actually describing — not Japanese literary studies as a discipline with clean edges, but a network of people with varying degrees of connection to each other and to a set of literary texts and critical traditions, with the network's density and topology changing over time. The nodes with the most connections are not always the most famous scholars; the edge types that cluster most tightly are not always the ones the field's self-description would predict. Looking at it for the first time produces something like the experience of looking at a city from altitude — the infrastructure you knew was there is suddenly visible as infrastructure, and the patterns it forms are not quite the ones you expected.
VIII. Translation
One question the 2018 essay gestured at but could not answer quantitatively is the relationship between translation and scholarly attention: does English translation of a Japanese author tend to precede North American scholarship on that author, or follow it? The intuition behind the question is obvious — scholars cannot engage seriously with authors they cannot read — but the intuition may be wrong, or may have been wrong in one era and right in another, or may describe some authors and not others. With translation data going back to the 1870s and dissertation and journal article data going back to the 1920s, it is now possible to measure the lag directly.
For each of 643 authors with at least three English literary translations and a datable first scholarly mention in English-language dissertations or the four flagship JSTOR journals, I computed the gap in years between first English translation and first English scholarly mention. A positive lag means translation preceded scholarship; a negative lag means scholarship preceded translation. The overall median is +9 years — translation leads scholarship by about a decade, on average — with 56% of authors showing translation-led patterns (lag \> 5 years), 18% simultaneous (within five years either direction), and 24% scholarship-led.
The aggregate figure, however, masks a historical arc that is the more interesting finding. The median lag by decade of first English translation runs: +35 (1930s), +21 (1940s), +17 (1950s), +11 (1960s), -2 (1970s), -10 (1980s), -8 (1990s), -19 (2000s), -19 (2010s). The sign flips in the 1970s and never comes back. Authors first translated in the 1930s through 1960s were, on average, translated a decade or more before the North American academy got around to them; authors first translated since the 1980s are, on average, being written about before translation or nearly simultaneously with it.
The period breakdown tells the same story from a different angle. Meiji-era authors — the Akutagawa, Kawabata, Sōseki, Tanizaki, Dazai, Ōgai generation — show a median lag of +18 years, with 76% translation-led. Premodern authors are similar at +17. The Taishō/early Shōwa generation (Mishima, Ōe, Abe Kōbō, Endō) is nearly split at +5, with only 47% translation-led. Postwar authors flip entirely: median -14, with 66% scholarship-led. The field's relationship to translation has structurally inverted over the course of its history.
The individual author figures are worth pausing on. Akutagawa was first translated into English in 1930 — by Asataro Miyamori, whose anthologizing work planted a lot of seeds that bloomed slowly — but does not appear in English-language dissertation titles or journal article text until 1967: a lag of thirty-seven years. Kawabata first appeared in English translation in 1951 and first appeared in English scholarship in 1969, just after the Nobel Prize; the Prize did not initiate the translations but it clearly initiated the scholarship, at an eighteen-year remove from the translations. Ōe is perhaps the most striking case: first translated in 1959, but first scholarly mention not until 1981 — twenty-two years during which translations of his work existed in English with essentially no academic uptake, followed by a surge that had nothing obvious to do with new translations appearing.
The contrast case is Murakami, first translated in 1985 and first appearing in English scholarship in 1981 — a negative four-year lag, meaning scholars were writing about him in Japanese before the English translations arrived. Abe Kōbō shows the same near-simultaneity (+2 years), as does Mishima (+5). These are authors who entered the North American field during the period of maximum institution-building, when the translators and the scholars were often the same people or close colleagues.
What changed in the 1970s to flip the sign? The most likely explanation is the professionalization of the doctoral training pipeline. The first generation of North American Japanologists — Keene, Seidensticker, McClellan, Hibbett — were scholars who also translated, and who built the field partly through translation: producing the texts that would later be studied. By the mid-1970s, a second generation trained in Japanese language programs that had expanded substantially through the 1960s was producing dissertations on authors they were reading in Japanese, sometimes years before those authors appeared in English translation. The translation industry and the scholarly field had uncoupled. Translation remained important — the 56% overall translation-led figure means it still describes most of the 643 authors in the dataset — but it was no longer the prerequisite it had been for the field's founding generation.
The Sōseki lag (+11, first translated 1947, first scholarly mention 1958) fits cleanly into the corrected Meiji median and I'd cite it that way. One note: Ōe's lag of +22 uses title-only scholarly detection, which almost certainly undercounts him given "Oe" is a collision-risk surname. The full-text ATF figure shows -7 for Ōe, meaning he was actually being written about before translation if you count body text. For the essay I'd either omit Ōe's specific number or footnote the collision caveat, and lean on Akutagawa (+37) and Kawabata (+18) as the clean examples since both have unambiguous surnames and ATF confirmation.
IX. Conclusion
Conclusion
"On my way I looked in at the data room downstairs. The always diligent Kimura, with about four other younger workers, was devotedly working at classifying and marking a mass of miscellaneous materials and data, though they could not know when or for what purpose they would ever be used. This was, as it were, the kitchen that provided sustenance and information for the forecasting machine. They were immersed in factual if monotonous work, which, as long as they believed in facts alone, was satisfying. They were little concerned whether the machine was nourished or given indigestion by such facts. To tell the truth, I too preferred this kind of work."12
I'm not sure if I prefer this kind of work, but I see some of its benefits. Now if the data confirms these conjectures or overturns them, what will we have learned? What will still be necessary to interpret? Seven years have passed since the first version of this essay, and some preliminary answers are in, or I'm beginning to get clarity on them, but not all of them. The field of Japanese literary studies is, in aggregate, not dead, though the job market data would have given any practitioner reason for some significant panic. The number of jobs did not crest in the early 1990s as I projected in 2018 — the crest came later, in the mid-2000s, and the decline has been steeper and more prolonged than I anticipated. What I did not project in 2018, because we had not experienced the pandemic or the reopening, was the inversion of 2024–25, the first year since 1988 in which available positions seem to exceed the number of PhD graduates (but perhaps this too is because we don't have the data on the number of PhDs yet, as some dissertations are embargoed and other universities are late in posting data). So if that signals genuine recovery, merely a temporary convergence of demographic factors, or a lack of data is not something this data can tell us. The data make these questions visible. The interpretation (and perhaps more data) is still required.
The theory finding more or less confirmed my instinct — its heyday measurable in the JSTOR journals at roughly a decade's remove from European Studies, concentrated in the 1990s rather than the 1980s. The dissertation data confirmed and complicated the "women" finding from 2018: gender and sexuality constitute a coherent and sustained intellectual cluster, rising through the 1990s and plateauing rather than declining, which is not what the backlash narrative about theory's retreat would have predicted and also not what an expansion after queer theory might have made us expect. The monogatari \> shōsetsu pattern I noted in 2018, somewhat tentatively, holds at nearly double the scale. That these things are confirmable across a dataset that grew from 1,545 to 7,922 dissertations is its own kind of reassurance about the reliability of the method, or at least its consistency.
What I did not predict, because I did not have the data to predict it and would not have thought to ask, is the translation-scholarship sign flip. The median lag between first English translation and first English scholarly mention runs from +35 years in the 1930s to -19 years in the 2010s, crossing zero in the 1970s and not returning. This describes a structural transformation in how the field accesses its objects: from a field that required translation before it could read, to a field that increasingly reads before translation arrives or in lieu of it ever arriving. The data shows this shift happening; it cannot tell us what was gained and lost in it.
What surprised me more, though I should perhaps have predicted it, is the conference data. That 41.7% of presentations by Japanese literature scholars at MLA occur outside Japan-themed panels — in sessions on narrative theory, ecocriticism, world literature, translation studies, gender and sexuality — is either a sign of intellectual vitality or a sign that the administrative category of "Japanese literary studies" has begun to describe something considerably narrower than what scholars in the field actually do. I suspect both. The match rate gradient from AJLS (76.7%) to SCMS (21.3%) traces something real about where the boundaries of this field are and where they are becoming porous (and maybe something about a media studies that assumes it can read work from around the world without local knowledge training as has long been the case in the social sciences). Whether the porousness represents health or dissolution is not a question I know how to answer with data.
I still have the heebie-jeebies about some of these methods (and maybe moreso now with the hep of AI), for the same reasons I named in 2018 and then some new ones. Academic programs are still asked to assess themselves on metrics not unlike these, and the distance between a state-of-the-field essay and a department self-study or strategic plan is less comfortable than I would like. Lest we fall complacently satisfied by the good and useful work of "classifying and marking a mass of miscellaneous materials and data" — like the narrator of Abe Kōbō's prescient Inter Ice Age 4, written at the dawn of the information age in 1958–9 — we as humanists, as readers of literature, must insist on resisting such work as the end of our work. That said, it can remain one beginning of our work among others. My dataset has grown considerably more powerful since 2018 and the power is precisely what makes me want to be careful about what I am describing. Source criticism is the first lesson of any humanist, and scale does not circumvent that lesson but rather blows it up to an even greater level of importance.
Facts or data alone have never spoken, nor have they made argument. What the past seven years of this project have done is increase the resolution of the picture considerably, and higher resolution reveals details that lower resolution obscured — the sign flip in the 1970s, the inversion in 2024–25, the cross-disciplinary drift — while leaving the interpretive questions exactly as open as they were. Like a camera enthusiast or HDTV early adopter who just wants more resolution, we can chase the infinite regress of data quite a while without finding satisfaction.
More like a carefully tilled plot than a broad and wide field, our area of play in a given year produces a few heirloom vegetables, maybe an award-winning fruit, and some solid dietary mainstays. What the data can do is tell us, with considerably more precision than before, how the soil has been tended, which varieties have thrived, and where the edges of the plot appear to end. Whether the plot is expanding or contracting, whether what grows at the edges is still part of the same garden — that remains a question for the people who work in it.
I have feelings about the state of the field. Hunches. Things that must be the case because of my casual observations about the field through the 20 years in which I've been a part of it first as a grad student and then as a postdoc, for a while as junior professor, and now as a member of the tenured elite. But are my feelings valid? Are they borne out in something like objective reality? What would be a good way of checking my own assumptions? What would be something like the objective reality of a field of intellectual inquiry? I have proposed to delve into these issues in this article to examine our field through one of its many problematic methods broadly named digital humanities.
But to get a grip on the viability of this extractive line of data inquiry, we should first recognize that Area Studies has long suffered from a fetish for data about the other. Or rather Area Studies is a discipline founded on the extractive principles of its imperial origins; what area studies has extracted of course was always supposed to be data. In this sense, data was a form of information digestible, yet not quite fully digested. A raw material extracted by linguistically and culturally nuanced experts in the field to be churned or crunched elsewhere by those who were not so compromised by closeness to the cultures of inquiry (to those who always value numbers over words, presumably by those in economics, sociology, and political science—disciplines more traditionally engaged in non-culturally or linguistically nuanced theory, disciplines that might more readily translate to cashing in on the encounter with the other economically or geostrategically and more often than not both). Linguistic expertise in area studies cultivated for fact-based analysis about places that are not here (wherever here may be) have been the mainstay and ground for studies about non-European and non-Anglophone places, be they from the global south, the global east, or the global mid-rift. Our intimate understandings of other places and peoples because we ourselves are hybrids caught between two cultures has had value in the academy and beyond. So what it means to be extracting data from a field routed in extractive data practices with dubious politics is itself to be held with suspicion. And this is compounded with the general cultural presence of and my specific use of AI here. AI is the latest capitalist engine that grinds data to drive a capitalism that is at once familiar and defamiliarizing.
And further, as the incessantly globalized world seems at once more homogeneous and more compact somehow today with our intertwined digitized networked assemblages and our ever-improving machine translations, many have claimed to see the end of the necessity of the humanistic study (be it in the guise of language study, literary study, cultural study, or historical study), as though with globalized English, the increased speed or seeming simultaneity of message transmission and increased connectivity comes an actual reduction of the distance between human A and human B or an enhanced intimacy, an intimacy 2.0. And in this fetishistic view, such culture data extraction seems almost too easy. Indeed, in this article I have only dabbled, grabbing the data that was possible to grab in a short time under limited resources (slightly less limited with the aid of AI in 2026 but still constrained). I could have and should have gone further. But deadlines, the limits of my digital know how, and budget means that there is always more work to be done. The vision of being able to grab and analyze something like "all of the data" about even something as narrow as "Japanese literary studies in English" is a dream sharing much with the library at Alexandria, one so common in our utopian beliefs in the coming of a "singularity" in which everything is digitized.
This utopian belief in the coming convergence culture of a "singularity" is hailed as the end of the human, the dawn of true planetarity, a time when humans will no longer be bound by our mortal coils and consciousnesses will be eternal in some cyberworld of our own devise. Whether these bombastic terms are realistic or not, the perception of such radical changes by a few has already begun to have real effects on more mundane beliefs in more watered-down versions in the direction of this singularity. Such real changes in the academy and governmental (lack of) support for the humanities became most recently pressing around 2008 with the combined economic downturn and its coincidence with the push for STEM education (but it goes at least back to the Reagan era and the large scale defunding and or scaling back of programs like FLAS).13 The economic downturn was almost immediately felt nationwide in fewer students studying abroad.14 At my institution, the big drop in the humanities majors (which is now nearly universal around the nation) would take a few years to kick-in, beginning really in 2012; and yet Japanese (though taking a hit) remained statistically speaking stronger than say English or History which were nearly halved in numbers in the course of a year or two. And that was true before the pandemic. What has happen to the humanities since has only deeped the crisis! So, of course, absolute numbers remain higher in those more traditional fields but they were hit relatively harder than more niche fields like Japanese studies.
So if we stack up why this happened, it is easy and right to point at least one finger at neoliberal corporatist university practices and at financial speculation in the information age, as Mary Poovey has done with her suggestion that we live in algorithm crisis of a modelling age that led to financial ruin through incessant speculation. The housing crash itself being the product of bundling and outsourcing risk, itself a product of the calculations digital humanists find themselves engaged in, only using non-financial data. And we know that such modelling has also been applied to our own academic institutions abstracting what work the university has been thought to do for centuries (producing knowledge and understanding) to a measurable set of outcomes (publication numbers for instance). It seems clear now that the "outcomes" (to use the University-speak in vogue today at least at my institution) of the implementations of such administrative numerology today is clear. The shuttering of humanities programs that cease to fulfill the mission (which has been redefined as the production of more beans; not better ones; in fact, this numerology has no concern for the variegation amongst beans or the notion that there may be peas worthy of counting too or the notion that some nourishing foods have no bean equivalents.)
And with another finger we might want to point at other information age technologies such as digital social media platforms. Surely these net cultures that purport universality (but which come equipped with active blinders over which we only maintain partial control) have something to do with the increase of insularity and decrease in willingness to study other cultures in ways they have been previously studied, in the drift from studying print media. But as we may be more homogeneous in the fact that so many of us seem to use google and Facebook, X, Line, or Instagram we are also more divided by these very bubbled discursive economies or siloed media towers. This claim of global flatness or singularity or planetarity overlooks the unevenness everywhere. On the one hand, perhaps, we are getting there—I use google, they use google. On the other hand of course, WE will never get there, because this WE is always curtailed. So surely Web 2.0 has already contributed to a flattening of a certain class of digerati in the world, a move towards globality and singularity, but even within this global subculture or subgroup we have witnessed increased in bumpiness in the various move towards blowing it all up (we need to have looked no further than the rise of the netto uyoku for a sense of this at the turn of the century in Japan; this may have been the biggest failing in recent years of teaching Japanese culture in the US— that we thought their inflammatory discourse problem could not also be ours; witness the rise of right-wing and violent groups on 8chan a mere spin-off of 4chan which was a spin-off of the Japanese 2chan).15
And then of course there is the great disconnect offline—those who never connect or connect differently from we digerati. Of course, efforts at universal computerization (for instance, the one laptop per child project) promise to bring sustainable solar powered cheap computing everywhere, and yet connectivity has proven to be a deeper problem than previously imagined. In Japan internet penetration hit 95 percent via the spread of cell phones early this century. But that still leaves 5% disconnected from all the would-be flatness and singularity—5% that is left behind (or at least left out) by new media. Of course, that percentage is higher here in the US. Then there is the question of unevenness in the connection: Most of the 95% in Japan are connected through phones, but far fewer use computers. In a recent study less than 50% of the Japanese working class was deemed to be computer literate.16
So, of course, this new media tower or bridge of instant connection and grand equality is as fantastic (mythical) as it is harrowing. And so we have good reason to resist the taunts of the information age, cyber cultures, and digital humanities that have accompanied them—great reasons to resist the notion of our cyberization, great reason to drop out of connectivity. Great reason to be fearful and skeptical of using AI (not to even begin to get into the environmental disaster of it).17
Indeed, when it comes to the local version of the cyberiad, we are on even firmer footing for resisting. The notion of Digital Humanities is ridiculous: If we all just become social scientists the common universal language of math or emoji will allow us to unite. Aliens, as we know from the playful apex of Spielberg's career, speak colors and music. So too (this line of thinking would have it) are we posthuman academics destined to program in R or Python and learn about statistics to gain greater audience or at least use AI in part of our workflow. To take up computative methods for humanistic research then might seem to give up the fight before it has really begun. But even the best social scientists and physical scientists continue to make the ultimate human error of confusing correlation for causation. For taking a preponderance of correlation to mean causation. And we might note the correlation of the rise of DH and the demise of humanities may not be causal. Or rather they may both spring from a common source—neoliberalism. And the effect has been that sociological studies are largely deemed to have a deeper grasp of important issues that effect us all than humanist ones.
In literary and cultural studies there are essentially two methods of reading, the lie of the text also known as structuralism (we read only the text) and the lie of historicism (connections to other data points matter—historical events, biography, gender, paratexts, intertexts). The first is a productive lie because it gets us to focus and do close readings by pretending that the only thing that matters is the text. Of course, this is a lie because no text operates in a vacuum of other data. The second is a productive lie because meaning is made by connecting two things previously thought unconnected. It is a lie because by connecting two things we've typically correlated them without proving causation, thereby repeating the mistake of our colleagues in the social sciences. Flawed though it is, the first method has been productive, making us better readers, and understanders of how texts are structured. Flawed though it is, the second has reminded us that no text is an island. The two present an onotological hermeneutical circle in which we can categorize pretty much all humanistic scholarship. Choose your ontology. One minute in one circumstance, I'm comfortable with the text qua text. In another, I caution myself to read in context. Neither of these methods makes me a bad scholar or a good scholar. What makes me that is how I use them or abuse them, how conscious or unconscious I am about their existence.
Thinking about humanistic problems by using digital tools can work to supplement either method without displacing them. And in the end the same will continue to be true. The tools will not make my scholarship bad, the critique or lack of critique will. The problem arises around a humanist mysticism around social/pseudo sciences and math (a kind of numerology employed by DH scholars to the benefit of DH scholars (who repeat dodges such as: the algorithm is too complex to get into; only the computer can really fathom the number of calculations we are talking about; but look what the computer churned out)) because of these dodges, the ontological choices that DH makes tend to be obfuscated. They don't seem like choices. So rather than digging in and critiquing the models, we humanists tend to reflexively jerk our collective knees and critique the entire thing. Throw the good data out with the bad, the useful method out because of the bad faith use. In other words, there is nothing wrong with DH; there is a lot wrong with the way scholars tend to do DH. The emphasis on method and scale at the exclusion of humanist questions appears again and again. Because DH is a pain for us humanists. (Learning to program. The foibles of OCR optical character recognition (especially with Asian languages from long ago). The data collection and cleaning. If I have to do all of that, I might as well just read the fucking poem!!! ) So that by the time the exhausted/just trained DH scholar finally presents, they claim their method as a finding. Rather than recognizing that they still have to do the work of interpretation.
Disclosure: My first book is a DH book. But no one read it that way. No reviews mention that. Maybe it was because I successfully disguised the new positivism as the old positivism. But I think I know the reason; it was because any of the insights that began there, did not end there. The data was something that appeared in the first quarter of a chapter and the rest of the chapter was moved beyond it. The data was useful as a launching tool. Like a new dictionary or new concordance, you don't have to use it. You do just fine without it. But maybe the new tool will show you something or allow you to see something you would not otherwise have been able to see. Maybe you'll be able to make a bigger, better, or different claim.
How tangible is all of this at the level of the micro field in which we find ourselves? It is not that there is anything inherently different and, therefore, worse about the positivism of DH than that of traditional Asian Studies writ large, but the same critiques of Asian Studies by concerned or critical Asian scholar luminaries like Harootunian and Miyoshi hold for the new positivism. Of course, if by DH we mean uncritical positivism, it is flawed and must be resisted. If we rethink DH to include all work in the humanities that uses a computer, then we are all already digital humanists today whether we admit and like it or not. There is no analogue humanities today possible; all humanities is always already digital humanities, just look at your finger. I suspect that the real problem is the work that calls itself DH (and in 2026 I'm not even sure that much of it still does so computational humanities or cultural analytics also seem fair game now) too often is characterized as simply boring work for bringing social science methodology to bear on humanist questions with little or no immediate or obvious pay-off for humanistic inquiry. So it seems like a weak cousin to the social sciences and giving up on the humanities to we true humanists. But this work is neither a zero-sum space that needs to take resources form more traditional reading methods, nor one that obviates those reading methods in any way. At worst it sidesteps humanist questions; at best such methods can supplement and augment, enhance and enrich them.
In addition, we have to ask ourselves given the higher role such overt positivism in literary study has played in the Japanese academy for so long, who are we to criticize solely on that basis. If resistance to DH is just an allergy to numbers, then it is the same old familiar border patrolling about knowledge silos. If this is a critique of positivism, then let's go for it. The way to go for it is not simply to bury our heads in the sand, because DH is going away, but to dig in and expose how and why it is problematic and the limits of its use value. To what degree positivism is useful drawing as it does on the idea of an objective reality and to what degree it is bunk because facts (alternative and otherwise) are always in want of interpretation.
So let me give a sense of what I think the allergy is all about—the difference between hobbiest tinkering and the disciplined scholar delving into important issues—through one example. Recently I've been doing some old-fashioned archival work on photography. An amazing thing happens when someone manages to identify the place where a photo from the mid to late 19th century was taken based on a building in the background that no longer exists. This is done based on corroboration with other photos, historical maps, architectural plans, government documents etc. It is difficult, painstaking, annoying, time-consuming work. And when the answer is found some pleasure results. We have an ah-ha moment. But it doesn't last. At least it cannot last for some of us. For others, this sort of identification is the sole work of cultural or historical engagement. Today this sort of work tends to be done by museum curators, art historians, collectors, and hobbyists on the web. But it leaves the old humanist question I find myself asking my students: so what? Why should we care? This has been the place where the work of criticism or theory or literary scholarship has always begun, namely where the positivist ends their work. Literary and cultural studies have long sought to take up this kind torch—always asking why in a deeper way. But area studies have a positivist/hobbyist streak within them. After all we are translators, introducers, middlemen minorities trading in the cultural capital of elsewheres. And yet if this is all that we do, then we accede to the old extracative model. We provide the data for others who don't know it well to crunch or make meaning. But lest we fall complacently satisfied by the good and useful work of "classifying and marking a mass of miscellaneous materials and data" like the narrator of Abe Kōbō's prescient Inter Ice Age 4 written and the dawn of the information age from 1958-9, we as humanists, as readers of literature must insist on resisting such work as the end of our work. That said, it can remain one beginning of our work among others.
Most DH scholars too are like these tinkerers leaving to many questions unanswered. It tends not to be that the data selected and crunched are in and of themselves bad or wrong (we can always ask the question why this and not that no matter if our data is numerical photographic or discursive), but that the research questions and answers are not clearly defined and targeted. This is because the methods are difficult diverse and time consuming that scholars have been turned into hobbyists by them. Let me do this and leave well enough alone. So, it is not that we can simply write off DH, because it won't be written off. It is not going anywhere. So we should attempt to critique it from within but also salvage what is useful from it. Recognize its imperfections and embrace its utility.
Since I have not yet completed my data dive, I want to (in the spirit of the natural and pseudo sciences) layout here what one might expect from the impossible ideal of a complete dive, that is to propose some hypotheses and to also conjecture what interpretive work such data would necessitate after the collection and initial crunching of the data based on the limited work I have accomplished thus far.
First, I expect to be able to say the field of Japanese literary studies is far from dead based on the collection of data about our field. What I expect to find about trends in the job market from 1967 (the first year available from MLA) today is that likely the number of jobs in Japanese literature will have crested in the early to mid 1990s; that likely there are the fewest absolute number of jobs now (since 2010) that there have ever been since 1967; I have already noted that as a proportion of the total MLA job pie, Japanese studies has held relatively stable. So in a glass is half empty vein, it may be more accurate to say that at least the field of Japanese literary studies is dying at about the same rate as the rest of field as measured in jobs posted. As expected this data has show that greater emphasis in the 1970s was placed on language over literature, on linguistic competence rather than disciplinary area of research or period; that more tenure lines became available through the 1980s and 1990s; that the distinction between between modern and premodern will arose in the 1980s and was solidified in the 1990s. I would conjecture that I will be able to replicate a similar division between jobs that ask for language and literature alone and those that ask for dabbling in cultural studies with expanded definitions of literature occurring from the mid 1990s through 2000s (and I assume this will be correlated with a fading of job-ad interest in the premodern).
Second, it seems clear that the rise of theory in the field as measured by keywords and name drops in major journals is measurable. The prevalence of interest in topics such as canon shifting topics might also be traceable (for instance the above mentioned growth of interest in "women's literature" as found in dissertations). We might even conjecture that data will be able to tell us whether new trends in publishing start from dissertations where young innovators are first strutting their stuff or from second books after scholars have gotten out from being disciplined by their advisors.
Now if the data confirms these conjectures or overturns them, what will we have learned? What will still be necessary to interpret? Surely knowing for sure that theory had its heyday at a decade delay from the general heyday in European Studies in the 1980s and was, instead, popular in the 1990s in Japanese studies will confirm my instinct; but what if the data doesn't show this. Will I need to readjust my view of the history of the field in relation to other fields of humanistic inquiry to make Japanese literary studies more of a trend setter than a follower? What if the rise of film and media jobs is evident far earlier than my hunch of the 2000s? Will that necessarily mean literature no longer matters? How can I be sure if seemingly canon expanding words like "women" used in titles of dissertation correspond to a qualitative change in the shape of Japanese literary studies at large and not just simply the name for a subfield ghetto-ized from the rest? The answers to these lines of inquiry necessarily require leaps from the data, deeper reading than such statistical observations may allow, but also interpretation and, yes, critical thinking.
Now one reason I think such data to be a helpful launching point is because of the scale things I hope to find in the data. If I were looking for the minute and intricate understanding of a specific poem, I don't think I would care to think about data. But since, in the context of a state of the field, I'm interested in some long term trends, I think that the resources of data available are remarkably useful.
This does not mean that the entire process is free from giving me the heebie-jeebies or pause. I don't like the fact that some of the methods of our destructions would be used by us. That is (at least at Penn State) academic programs are asked to assess themselves on almost precisely these kinds of metrics. We are asked to, for instance, identify key journals in our field and then publications in those journals are given more weight than those not. It is not that numerical data or computational linguistics methods can't be helpful to questions we have always asked in the humanities, they have always been helpful, but that the methods are not in themselves answers and we need more people thinking critically about how to use them and how not to abuse them.
But I think part of our allergy to the methods comes from the high bar for getting started, part from lack of ingenuity by some who have engaged in its methods, and part to end with method rather than using such methods as yet another tool of philology no more or less important than an attention to facts in other parts of the traditional humanities. Facts or data alone have never spoken nor have they made argument. Therefore, less than a revolutionary method to replace the humanities as we know them, DH is simply its latest supplement.
More like a carefully tilled plot than a broad and wide field, our area of play in a given year produces a few heirloom vegetables, maybe an award-winning fruit, and some solid dietary mainstays. If this plot is organic or chemically produced, if it derives sui generis from the material soil or is genetically enhanced with splicings from other disciplines, in daily practice we seem not to care. Only during times of crisis and achievement do we tend to take stock of the harvest and its potential future survival under the constant state of emergence and precarity, contingency and risk. Sustainability and conservation of the crop may seem less important here than adaptability, innovation, and progression. But it is precisely when that determination has been made that we should take stock of what is given up in that transition.
Data & Visualizations
The essay above draws on seven interlocking datasets assembled over 2023–2026. The visualization project is organized into four research branches, six guided tours, and a full browsable index. Each entry point below opens its own navigation hub.
Browse by Research Area
Scholarly Networks
→Advisor–advisee genealogies, citation networks, authority rankings, and intellectual flow across 7,922 dissertations and 3,075 scholars.
14 visualizations · 5 network types
Conference Presentations
→13,592 presentations across five venues (AJLS, AAS, MLA, ACLA, SCMS) from 1992 to 2026, with co-paneling networks and topic evolution.
43 visualizations · 5 venues · 34 years
Content Analysis
→Topic clustering across 6,874 dissertations using NLP classification, plus journal term trends across 29,311 articles in five journals.
10 visualizations · 20 topic clusters
Career & Job Market
→Career trajectories, institutional pipelines, and the history of the Japanese literature job market from 1968 to 2025.
3 visualizations · 1,571 career paths
About & Methods
→Data sources, methodology, network construction, NLP classification approach, and caveats about coverage gaps.
8 data sources · documentation
Guided Tours
Curated sequences of visualizations organized around specific research questions.
How has the field changed since 1990?
→A curated sequence tracing transformations in dissertation topics, journal content, and conference presence over 35 years.
Which institutions dominate?
→Placement patterns, advisor concentration, and conference representation across North American doctoral programs.
Who studies what?
→The relationship between scholarly training, institutional affiliation, and research specialization.
History of the job market
→From oversupply to undersupply: the structural shift in Japanese literature hiring from the 1990s to the present.
Full Index
Browse all visualizations by branch, filter by topic or method, or start a guided tour from the project front page.